Получить ответственный подход в продвижении вашего проекта.
Свяжитесь с нами прямо сейчас!
Свяжитесь с нами прямо сейчас!



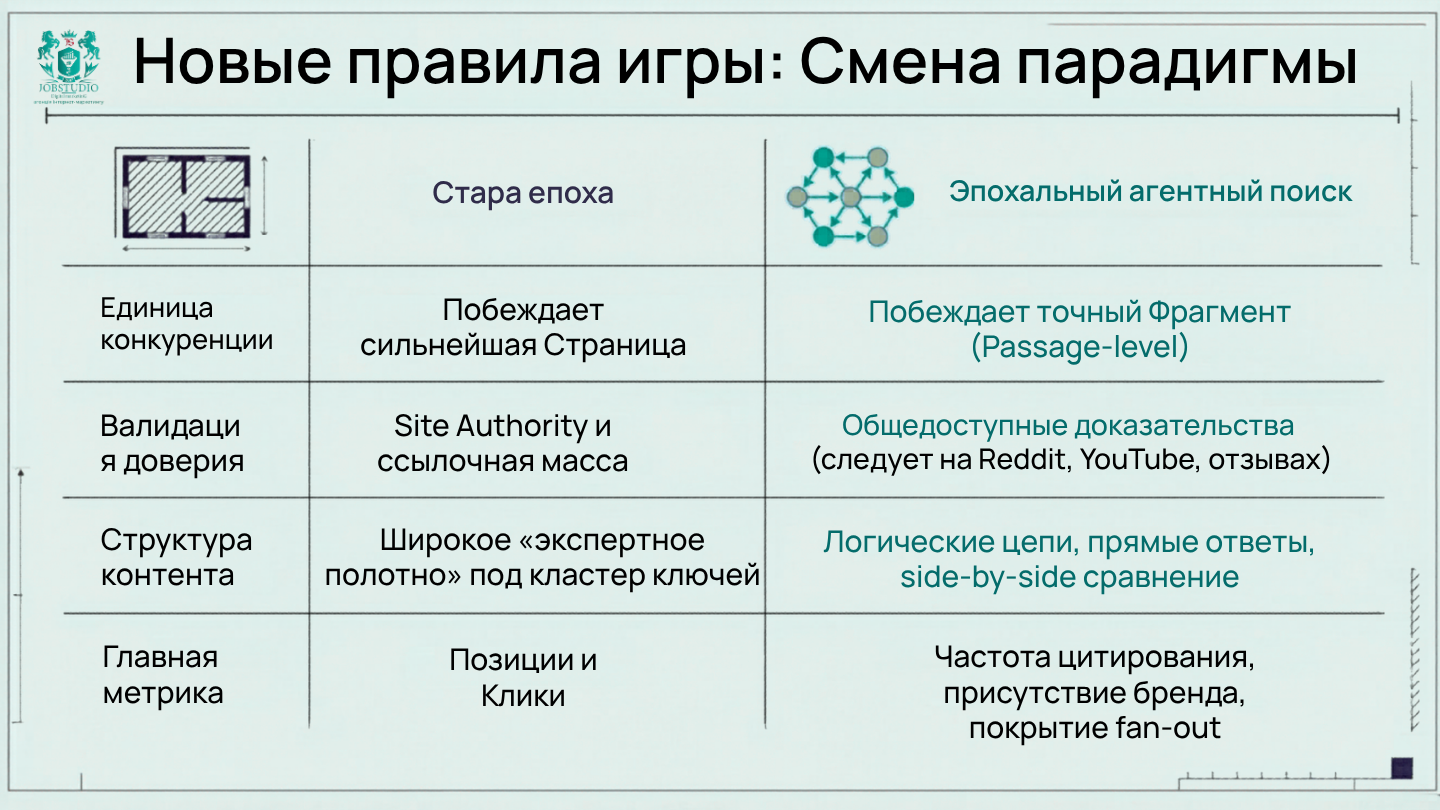
Сегодня говорить «SEO = Google = позиции = клики» уже недостаточно. Не потому, что Google перестал быть главным игроком, а потому, что само поведение пользователей при поиске стало более разнообразным. Аманда Нативидад, вице-президент по маркетингу SparkToro, формулирует это очень точно: search is a behavior. Люди ищут не только в Google, но и в YouTube, Reddit, Amazon, AI-интерфейсах и сообществах, где они собирают доказательства, сравнивают варианты и проверяют доверие к бренду.
Содержание
Важно, что это не «антигугловская» история. Наоборот: исследование Рэнда Фишкина для SparkToro показывает, насколько Google по-прежнему гигантский — по трафику браузера он равен следующим 13 крупнейшим сайтам вместе взятым. Но именно поэтому поиск часто присваивает себе заслугу за спрос, который был создан ранее в других точках контакта: в соцсетях, медиа, письмах, сообществах, подкастах, отзывах. Из этого следует неприятная для старого SEO мысль: выигрывает уже не тот, кто просто «стоял в топе», а тот, кто построил более сильный публичный след бренда.
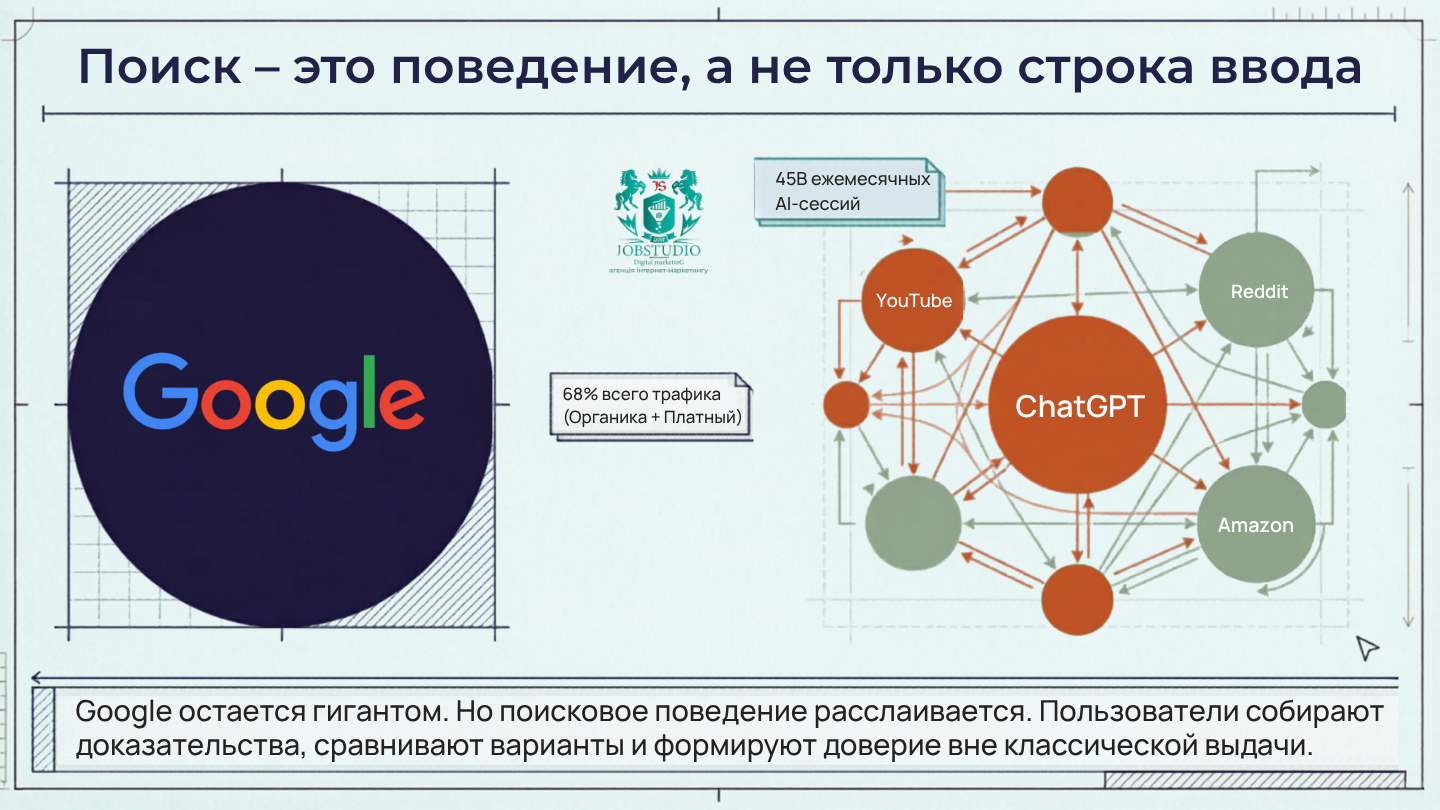
Если посмотреть шире, это не умаляет значимости поиска как канала. Еще до эры ИИ компания BrightEdge отмечала, что органический и платный поиск обеспечивали 68 % всего отслеживаемого трафика веб-сайта, а доля органического поиска в среднем по отраслям достигала 53,3 %. В B2B комбинированный поиск вообще давал 76% трафика, а B2B-компании получали вдвое больший доход от органического поиска, чем от любого другого канала. То есть поиск не исчез. Он просто перестал быть однослойным.

Отдельно стоит учитывать и масштаб AI-интерфейсов. По оценке Graphite, использование AI уже составляет 56% от объема поиска по всему миру, а в глобальном масштабе AI получает около 45 миллиардов ежемесячных сессий; при этом 83% использования AI приходится на мобильные приложения, а ChatGPT занимает 89% мировой доли рынка AI. Это не официальная статистика Google или OpenAI, а рыночная оценка Graphite, поэтому относиться к ней стоит как к сильному индикатору масштаба, а не как к абсолютной истине. Но само направление очевидно: ИИ уже не «игрушка на обочине», а реальный сегмент поискового поведения.
В JobStudio мы видим это так: борьба идет уже не только за место в SERP. Она идет за право быть найденным, правильно истолкованным, процитированным и выбранным в среде, где решение все чаще принимает не человек, просматривающий 10 ссылок в поиске Google, а система, собирающая ответ из десятков источников.
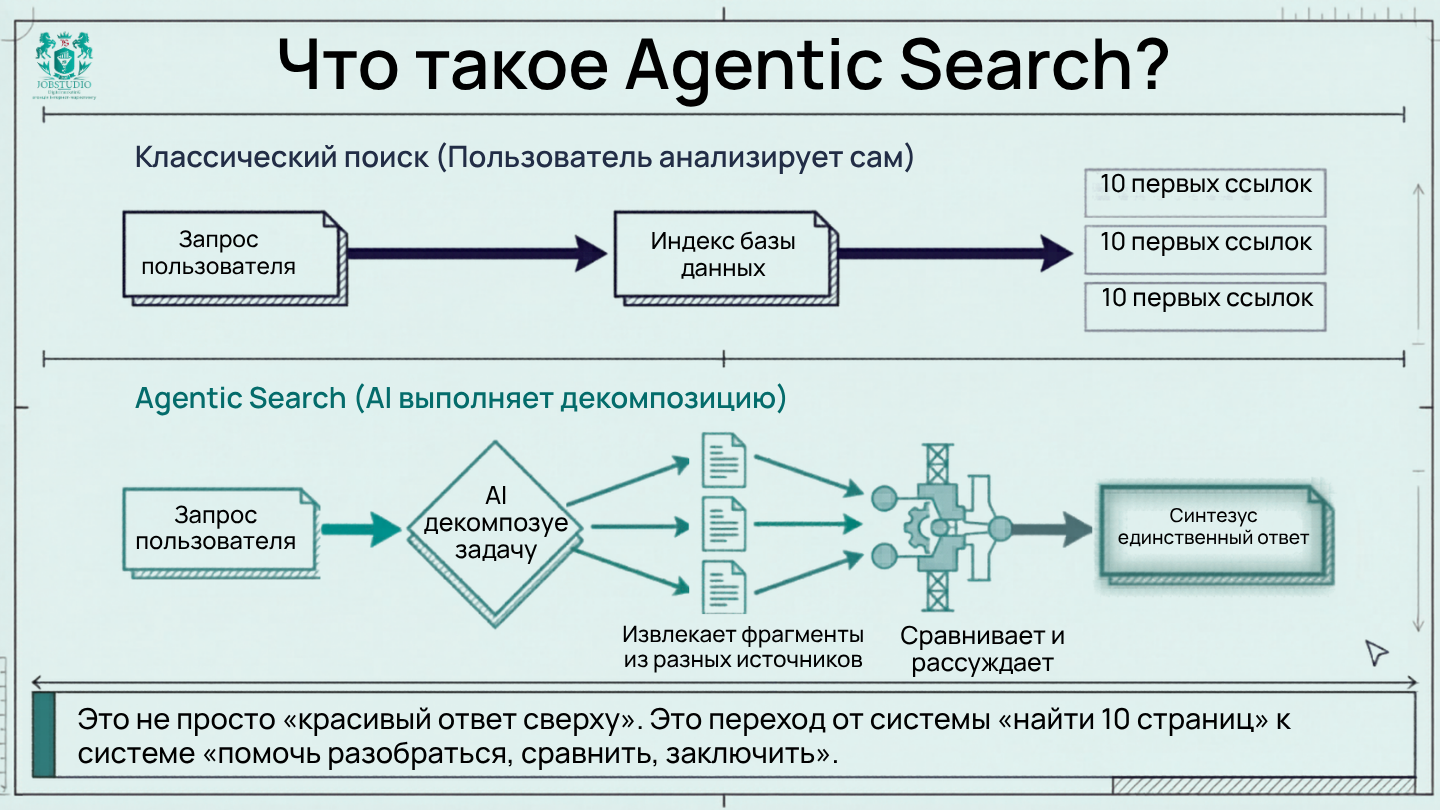
Agentic search — это не просто поиск с красивым ответом вверху. Это модель, в которой система не ограничивается одним запросом пользователя и одним списком документов. Она разбивает задачу на части, генерирует уточняющие подзапросы, извлекает релевантные фрагменты, сопоставляет их, синтезирует итог и только потом выдает результат. Именно поэтому AI Mode и AI Overviews следует воспринимать не как «еще одну фичу SERP», а как иную логику взаимодействия между пользователем, индексом и моделью.
Google уже официально объясняет это довольно прямо: режим AI Mode особенно полезен для запросов, требующих дальнейшего изучения, анализа или сложных сравнений. То есть система разработана не для того, чтобы «найти 10 страниц», а для того, чтобы «помочь разобраться, сравнить, сделать вывод». А дальше вступает в игру query fan-out: AI Overviews и AI Mode могут запускать несколько связанных поисков по подтемам и источникам данных, а также показывать более широкий и разнообразный набор вспомогательных ссылок, чем классический поиск.
Это хорошо совпадает с тем, что обсуждает рынок. Конференция AEO Conf 2026 была организована совместно компаниями Graphite, AirOps и Webflow именно вокруг темы того, как ИИ меняет поиск, цитирование и новую логику контента для LLM. А Майкл Кинг еще раньше предупреждал, что мы недооцениваем эффект памяти, персонализации, агентности и новых моделей подбора контента. В собственном разборе Google I/O 2025 мы тоже отмечали то же самое изменение: поиск становится не линейным, а диалоговым, контекстным и фрагментарным.
Самая большая проблема темы agentic search заключается в том, что она уже превратилась в рынок громких обещаний. Поэтому начинать нужно не с «секретных факторов ChatGPT», а с разграничения.
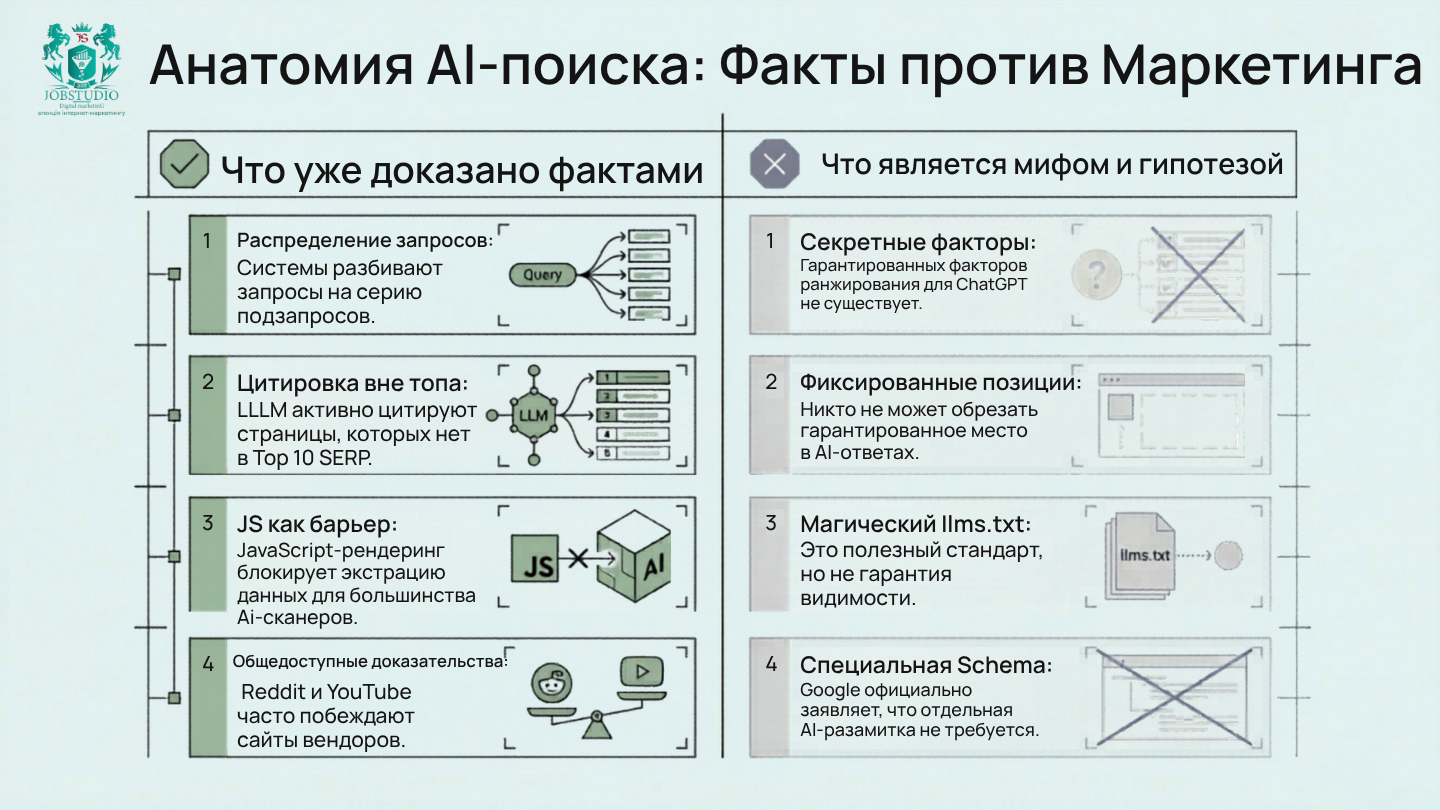
Что уже можно считать подтвержденным. Во-первых, Google официально признает query fan-out в своих AI-функциях. Во-вторых, AI-системы действительно могут цитировать страницы, не входящие в топ-10 классической выдачи. В-третьих, техническая экстрагируемость страницы имеет значение: в тестах Writesonic 9 из 11 элементов метаданных дали ноль, а ChatGPT, Claude и Gemini вообще не выполняют JavaScript при живой выборке так, как это привыкли представлять многие команды. В-четвертых, внесайтовое доказательное поле действительно имеет значение: Reddit в B2B SaaS часто появляется раньше сайтов вендоров даже по запросам общей категории.
Что пока следует использовать с осторожностью. Не существует публичного списка «факторов ранжирования ChatGPT». Нет оснований утверждать, что llms.txt уже стал стандартом, определяющим видимость во всех LLM. Нельзя честно обещать «гарантированное попадание» в AI-ответы. И даже сильные рыночные тезисы вроде «95% цитируемых доменов находятся в пределах первой десятки» или «60% подсказок содержат более 10 слов» стоит маркировать как конференционные или рыночные выводы, а не как официальную норму индустрии.
В JobStudio это правило звучит просто: мы не продаем чудеса. Если есть факт — так и пишем. Если есть рабочая гипотеза — так и обозначаем.
Query fan-out: что на самом деле ищет система
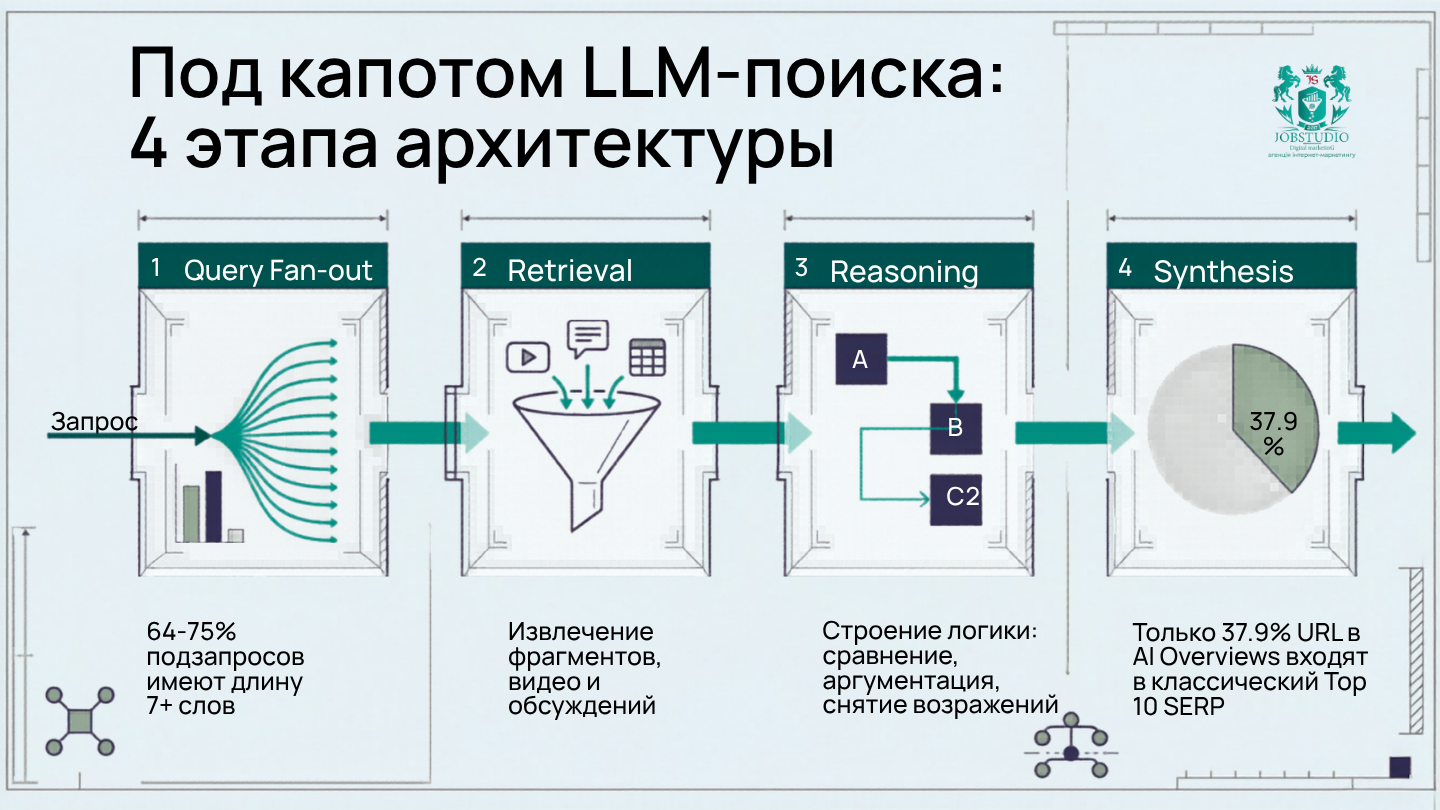
Самая большая ловушка старого SEO — представление о том, что пользователь ввёл один запрос, а значит, и конкуренция разворачивается вокруг одного запроса. DEJAN показывает, что реальность уже иная: при анализе производственных нагрузок они зафиксировали около 365 920 fanout queries в Google, OpenAI и Amazon Nova. И что важно, эти запросы значительно длиннее обычного классического поиска: в Google 64,9% fanout queries содержали 7+ слов, в OpenAI — 75,8%. Это очень весомый аргумент против подхода «главный keyword + пара вспомогательных ключей».
После fan-out система не «видит вашу страницу» в человеческом смысле. Она извлекает кандидаты: страницы, фрагменты, видео, таблицы, форумы, обзоры. Google прямо пишет, что особенности ИИ могут показывать более широкий и разнообразный набор полезных ссылок. Это означает, что конкуренция уже идет не только между однородными лендингами в топе, а между различными форматами доказательства: статьей, форумной дискуссией, YouTube-роликом, страницей сравнения, FAQ-блоком.
Далее начинается самое интересное. В нашем собственном обзоре Google I/O 2025 мы описывали это как переход от страничного мышления к цепочке рассуждений: система не просто проверяет, «соответствует ли страница запросу», а помогает ли конкретный фрагмент достроить логику ответа — сравнить, объяснить, подтвердить, снять возражения, дать сценарий. Именно поэтому контент с четкими причинно-следственными блоками, сравнениями, примерами и завершенными микровыводами выигрывает чаще, чем красивое, но размытое «экспертное полотно».
Последний этап — синтез. Система отбирает несколько лучших фрагментов и формирует окончательный сценарий ответа. Именно здесь становится очевидным, насколько опасно сводить SEO к формуле «мы в топ-10, значит нас возьмут». По данным Ahrefs, только 37,9% URL, процитированных в AI Overviews, также были в первых 10 блоках SERP. Еще 31,2% были в диапазоне 11–100, а 31,0% — вообще за пределами топ-100 блоков. В тесте только по blue links картина очень похожа: 37,1% в топ-10, 26,2% на позициях 11–100 и 36,7% вне топ-100. То есть AI-ответ — это не просто «топ выдачи, перетасованный LLM».
Если свести это изменение к одной фразе, она звучит так: новая единица конкуренции — не страница, а фрагмент. Один абзац может выиграть в прямом сравнении. Один список может попасть в топ результатов. Один блок сравнения может объяснить разницу лучше, чем вся страница конкурента. Это и есть практический смысл passage-level SEO, о котором так много говорят в контексте AI Mode.
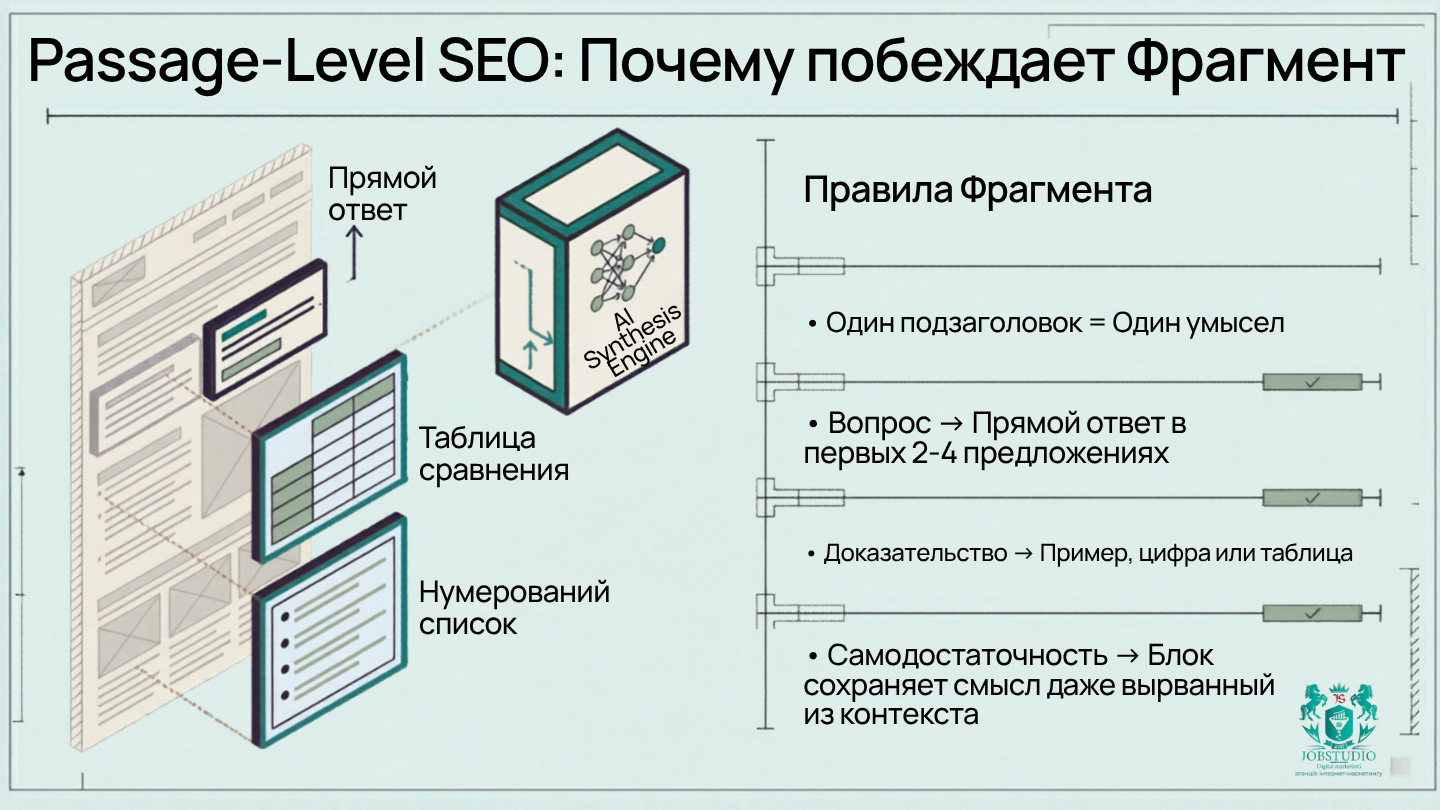
Отсюда вытекает новая дисциплина письма. Один абзац — одна законченная мысль. Один подзаголовок — одно намерение. Сразу после вопроса — прямой ответ. Далее — доказательство, пример или сравнение. Если фрагмент не может существовать отдельно, модель его чаще пропускает. Если же он самодостаточен, четкий и полезен, у него появляется шанс «выиграть» даже без доминирования всей страницы.
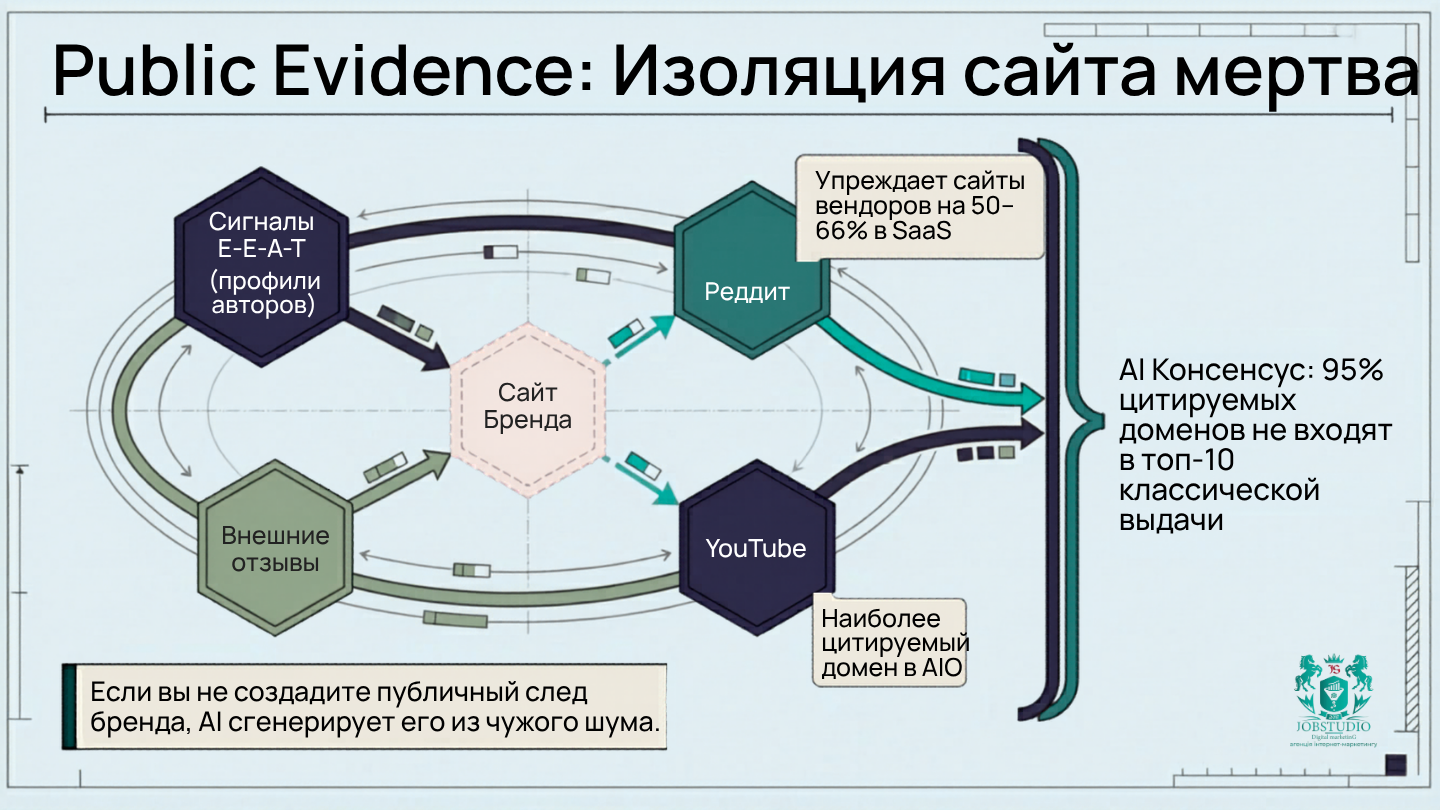
Сайрус Шепард высказывает очень убедительную мысль: наличие в поиске — это уже не просто PageRank, а целый пласт публичных доказательств, который заставляет результат выглядеть релевантным, надежным и заслуживающим клика. Это один из ключевых тезисов новой эпохи. ИИ и поисковые системы все реже доверяют странице «изолированно»; они оценивают, есть ли вокруг бренда след: упоминания, обсуждения, обзоры, профили, авторы, сигналы доверия, внешние подтверждения.
Росс Симмондс подкрепляет это цифрами. В исследовании Foundation Reddit одновременно опережал всех вендоров на 50–66% по общим ключевым словам в 3 из 4 SaaS-вертикалей, охватывая 957 540 ежемесячных поисковых запросов. И главное: это не «история об отзывах». 77% объема поиска, который выигрывает Reddit, приходится на общие ключевые слова категории, а не только на «лучшее», «отзывы» или «альтернатива». И что еще более показательно: по запросам из 6+ слов Reddit демонстрировал 73–100% коэффициент выигрышей в различных вертикалях. Когда поиск становится длиннее и разговорнее, сообщество выигрывает чаще.
Аманда Нативидад точно формулирует суть: поиск теперь происходит «в Google, Amazon, YouTube, Reddit, AI-инструментах». А Итан Смит в своих заметках после AEO Conf добавляет еще один полезный вывод: по их данным, 95% цитируемых доменов не входят в первую десятку, а Reddit был №1 с 2,36% всех цитат. Это стоит читать именно как сильный отраслевой сигнал: ИИ синтезирует консенсус, а не просто берет «самый сильный домен».
В практике JobStudio это означает одну очень простую вещь: если бренд сам не вынес свои сильнейшие аргументы в публичное пространство, ИИ и поисковые системы достроят его образ на основе чужих упоминаний, отзывов и шума. И далеко не факт, что эта версия бренда вам понравится.
После всех дискуссий об AI SEO полезно вернуться к реальности. Ниже приведены не «волшебные кнопки», а сигналы, которые чаще всего реально влияют на то, сможет ли система извлечь, понять и использовать ваш контент.
Если важный контент находится только в JS, таблах, динамических интерфейсах или загружается слишком поздно, часть AI-сканеров просто не успеет его прочитать. Writesonic показывает: ChatGPT, Claude и Gemini при live fetch могут видеть только необработанный HTML, а не полноценно отрендеренное клиентское приложение.
Вопрос в подзаголовке — ответ в первых 2–4 предложениях. Не обход вокруг темы, а ответ.
Google прямо рекомендует делать важный контент доступным в текстовом формате, а Writesonic показывает, что конвертеры-AI-сканеры чрезмерно упрощают страницу. Когда структура неясна, вы затрудняете не только пользовательский опыт, но и извлечение информации.
Не «эффективные решения», а «что делаем → что измеряем → какой результат получили». Модели охотнее воспринимают законченные, точные блоки, а не маркетинговые фразы.
ИИ не любит пустой пафос. Данные, примеры, фрагменты кейсов и факты повышают вероятность цитирования.
Именно такие форматы хорошо подходят как для машинного извлечения, так и для восприятия людьми.
Свежий, обновленный контент часто имеет больше шансов быть использованным, особенно в быстро меняющихся нишах. В своих конспектах с конференции Итан Смит особо подчеркнул, что устаревший контент цитируется значительно реже, чем обновленные страницы.
Google прямо указывает, что для участия в AI features не требуются «новые AI-файлы» или специальная схема. Однако структурированные данные, соответствующие видимому тексту, остаются полезным элементом общей SEO-гигиены. В то же время тест Writesonic показывает важное ограничение: сам по себе JSON-LD не поможет, если основное содержание не представлено в основном тексте.
Настоящий автор, дата обновления, профиль, опыт, связь с темой — всё это укрепляет доверие к странице.
Без профилей, упоминаний, сообществ, видео и цитат экспертов сайт уже не функционирует как самодостаточная крепость.

Хорошая новость от Google заключается в том, что не нужно придумывать отдельный «секретный технический стек для ИИ». Google прямо пишет: для появления в функциях ИИ работают те же самые лучшие фундаментальные SEO-практики, что и для поиска в целом. Страница должна быть проиндексирована, технически готова к показу в Google Search, и к ней нет дополнительных технических требований. Также Google прямо заявляет, что не нужно создавать новые машиночитаемые файлы, текстовые файлы с искусственным интеллектом или специальную схему только для AI Overviews или AI Mode.
Плохая новость заключается в том, что это не значит «расслабьтесь». Ведь те самые базовые требования теперь стали ещё важнее. Writesonic протестировал 6 ИИ-систем и 11 элементов метаданных в . Для 9 из 11 элементов результат был 0/6 — то есть ни один из шести протестированных ИИ не смог их прочитать, половина ИИ-помощников вообще не используют JavaScript как браузер пользователя, а те, что используют, тратят на страницу от 500 мс до 3 секунд. Через 3 секунды сканер уже перешел дальше. Если ваш критический контент появляется позже, для части ИИ он просто не существует.
Отсюда краткий практический технический чек-лист:
В нашей практике мы особенно остро ощущаем это на таких проектах, как Obmin.Finance. Там нельзя было «просто написать тексты под ключ». Нужно было еще до запуска заложить продуктовую архитектуру, мультиязычность, логику страниц, кластеризацию интенций и систему, способную стабильно работать с 28 000+ валютными парами и большим объемом динамических данных. Именно в таких проектах технический фундамент решает, сможет ли контент вообще участвовать в новой видимости.
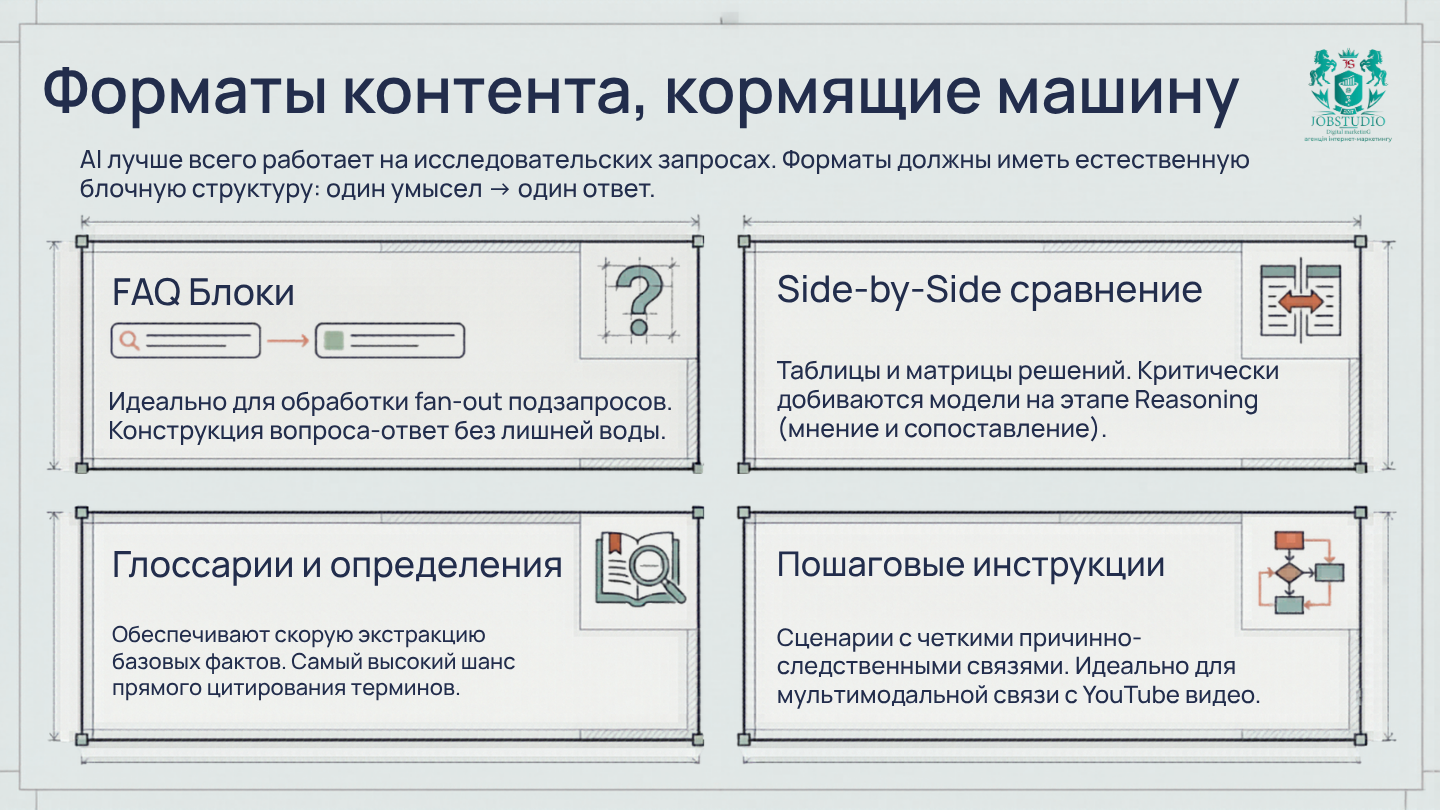
AI Mode особенно хорошо справляется со сложными запросами: исследовательскими, с акцентом на рассуждения, с акцентом на сравнение. Следовательно, выигрывает не любой контент, а тот, который помогает системе пройти эти этапы. Google прямо подсказывает направление: AI Mode лучше работает там, где нужно изучить тему, сравнить варианты, разобраться в нюансах.
Наиболее эффективные форматы здесь следующие: FAQ, инструкции, страницы сравнения, блоки определений, страницы-глоссарии, пояснения категорий, разбивка случаев, схемы принятия решений, таблицы и сравнения «side-by-side». Это не случайно. Такие форматы имеют естественную блочную структуру: одно намерение, один ответ, один вывод. Их легче извлекать, и они лучше работают в логике fan-out.
В JobStudio мы сталкиваемся с тем же в сложных продуктах. В кейсе Obmin.Finance контент не мог быть «для галочки». Нужно было закрывать информационные, аналитические и транзакционные интенты вокруг большого количества валютных пар, сценариев и рисковых вопросов. Именно поэтому контентный каркас пришлось строить не как набор статей, а как систему объяснений, FAQ, коммерческих страниц и экспертных материалов, которые одновременно привлекают трафик и укрепляют доверие.

Одна из самых недооцененных тем в дискуссии о GEO — видео. А зря. По данным Ahrefs, среди страниц, цитируемых в обзорах по ИИ, которые вообще не попадали в топ-100 Google по тому же ключевому слову, 18,2% составляли URL-адреса YouTube. А в целом YouTube составлял 5,6% всех цитируемых URL-адресов в выборке. Еще более впечатляет другая цифра: по данным Ahrefs Brand Radar, YouTube является самым цитируемым доменом в AI Overviews сегодня и за шесть месяцев вырос еще на 34%.
Практический вывод суров: если вы не предоставляете ИИ удобный видеоматериал, это сделает кто-то другой. Для практических и «пояснительных» ниш видео + транскрипт + структурированное описание уже не являются просто приятным дополнением. Это один из способов попасть в ту часть ответа, которая не сводится к абзацу текста.
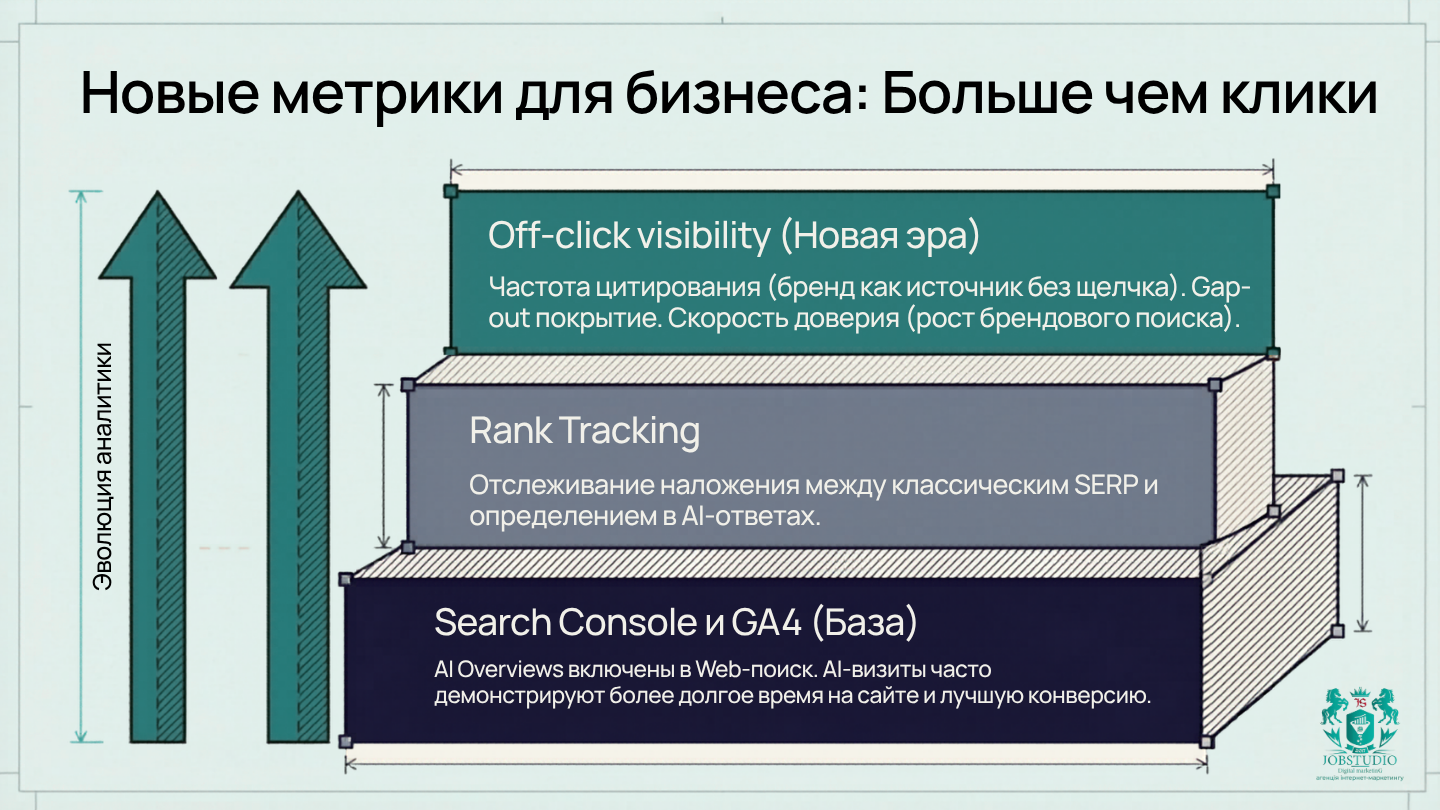
Google здесь тоже довольно прямолинеен. Сайты, которые появляются в AI features, включаются в общий поисковый трафик в Search Console в рамках обычного веб-поиска. А еще Google отдельно отмечает, что клики из AI Overviews могут быть более высокого качества: пользователи чаще проводят больше времени на сайте. Это важный сигнал для бизнеса, который до сих пор мыслит только CTR и позициями.
Итак, смотреть придётся шире. Да, Search Console остаётся базой. GA4 нужен для анализа качества трафика, конверсий и поведения пользователей. Rank tracking — для того, чтобы видеть пересечение между классическим поиском и AI-представительностью. А поверх этого нужно добавлять то, чего в старых отчетах почти не было: частота цитирования, видимость брендированных рекомендаций, присутствие без кликов, качество лида из AI-источников, fan-out покрытие, а впоследствии — и грубые оценки passage-level performance.
На практике это означает одну простую вещь: не всё, что важно в AI-поиске, приводит к кликам. Но то, что действительно влияет на продажи, рано или поздно проявляется в брендовом поиске, скорости завоевания доверия, качестве лида и способности бренда чаще становиться «предпочтительным ответом», а не просто «еще одним сайтом в выдаче».
Теория становится полезной только тогда, когда проходит через практику. И вот самый важный вывод из нашего опыта: новая видимость растет там, где есть система, а не там, где просто «дописали ещё одну SEO-статью».
В таких проектах, как Obmin.Finance, мы убедились, что классического страничного SEO недостаточно. Когда продукт имеет десятки тысяч сущностей, динамические данные, мультиязычность и сложные интенты, выигрывает не «самый красивый блог», а архитектура: как построена URL-логика, как распределены интенты, есть ли поясняющий контент, можно ли машине быстро сопоставить источник, намерение и доказательство. Именно поэтому мы пришли туда не только как «оптимизаторы текстов», а как соавторы структурной логики продукта.
И это хорошо согласуется с новой логикой AI-поиска. Если у вас есть убедительный публичный доказательный слой, четкие блоки ответов, техническая основа и система обновления контента, вы получаете не просто «больше шансов попасть в топ». Вы получаете шанс быть правильно прочитанными, процитированными и сопоставленными в новой поисковой архитектуре.
Худшее, что сейчас может сделать бизнес, — это считать, что все это «еще не актуально». Вот что обходится дороже всего.
Первая ошибка — думать, что достаточно просто попасть в рейтинг. Данные Ahrefs уже показывают, что значительная доля упоминаний приходится на сайты, не входящие в топ-10, а иногда и в топ-100.
Второе — продолжать писать цельные тексты, а не фрагменты. Если один блок не может ответить на одно уточнение, он плохо работает в среде reasoning.
Третье — скрывать основное предложение, цифру или доказательство в изображении или в визуально привлекательном, но технически пустом блоке. Writesonic показывает, как легко это становится незаметным для части LLM-краулеров.
Четвертое — жить только на сайте. Если у вас нет видео, упоминаний, сообщества, профилей, внешних доказательств, кто-то другой займет это место.
Пятое — оценивать только позиции и трафик. В новых условиях это уже не отражает всю картину.
Как мы сказали бы в JobStudio: проблема не в том, что «ИИ отнимает трафик». Проблема в том, что структура бренда в сети до сих пор не готова к тому, чтобы ее могла интерпретировать машина.

Проведите аудит индексируемости. Проверьте, представлен ли важный контент в HTML. Посмотрите на ключевые страницы не глазами дизайнера, а глазами сканера: есть ли прямые ответы, есть ли FAQ, указан ли автор, есть ли обновления, можно ли понять основную мысль без кликов, прокрутки и переключения вкладок.
Отберите 10–20 самых важных страниц. Добавьте блоки с описанием, FAQ, разделы сравнения, таблицы, аргументы, обновленные кейсы, четкие заголовки H2–H3. Вынесите убедительные аргументы в открытый доступ: статьи, профили, видео, сообщества.
Размещайте контент под fan-out-интентами: развернутые вопросы, сценарии выбора, сравнения, опровержения, нишевые инструкции. Параллельно укрепляйте внесайтовое поле — Reddit, YouTube, профильные площадки, упоминания экспертов.
Начните измерять не только трафик, но и новое присутствие: какие страницы используются чаще, какие темы лучше работают в длинных запросах, какие форматы обеспечивают более высокое качество посещения, какие страницы требуют обновления. Обновляйте сильные стороны, устраняйте лишнее, масштабируйте то, что действительно приносит видимые результаты.

Поиск никуда не исчез. И Google никуда не делся. Но изменилась форма конкуренции. Теперь бренд борется не только за место в SERP, но и за право существования:
Именно поэтому в agentic search побеждает не «самая оптимизированная страница», а наиболее убедительный набор публичных доказательств, который ИИ может быстро прочитать, сопоставить и использовать. Аманда Нативидад права: поиск — это поведение. Cyrus Shepard прав: решает не только рейтинг, а вся совокупность публичных доказательств. Ross Simmonds прав: путь покупателя давно выходит за пределы сайта бренда. А Google уже официально показывает, что его AI-функции работают через fan-out, рассуждения и более широкий набор вспомогательных ссылок.
Поиск не умер.
Умер подход, при котором достаточно было просто ранжировать страницу.
Это модель поиска, в которой система не просто находит страницы, а выполняет ряд действий: разбивает запрос на части, проводит уточняющий поиск, сопоставляет источники, синтезирует ответ и только потом показывает результат пользователю.
Агентный поиск — это более широкое понятие. AI Overviews и AI Mode — это конкретные интерфейсы Google, в которых уже реализована эта логика: fan-out, рассуждения, более широкий подбор вспомогательных ссылок и реакция на основе ИИ.
Нет. Google прямо указывает, что для поиска с помощью ИИ действуют те же самые лучшие базовые практики SEO, а страница все равно должна быть проиндексирована и технически готова к поиску. Изменение заключается не в том, что SEO «умерло», а в том, что его уже недостаточно сводить к позициям и ключевым словам.
Да. По данным Ahrefs, лишь 37,9 % URL-адресов, упомянутых в обзорах с использованием ИИ, находились в первых 10 блоках SERP; остальные часто приходились на позиции с 11 по 100 или вообще находились за пределами топ-100 блоков.
Вопрос поставлен неверно. Без технической базы контент могут не дочитать. Без сильного контента техника не обеспечит цитируемость. Необходима следующая комбинация: HTML-сканер, структура, прямые ответы, доказательства, авторство и внешний контекст доверия.
Часто задаваемые вопросы, инструкции, страницы сравнения, блоки определений, содержание глоссария, таблицы, разбор кейсов, схемы принятия решений и страницы с четкими прямыми ответами и доказательствами. Именно такие форматы лучше всего подходят для рассуждений и детализации.
Да. Росс Симмондс продемонстрировал это на данных SaaS, а Ahrefs — на AIO citations, где YouTube уже стал самым цитируемым доменом. Сайт больше нельзя рассматривать в отрыве от всего остального публичного пространства бренда.
Начните с Search Console и GA4. Google официально учитывает влияние ИИ на общий поисковый трафик в Search Console, а качество такого трафика следует оценивать по поведению пользователей, конверсиям и времени пребывания на сайте.
Общая базовая стратегия: HTML-сканеры, структурированный контент, прямые ответы, доказательства, авторство, внешний доказательный слой. Однако отдельные системы различаются по тому, как они обрабатывают метаданные, видео и сторонние источники.
Начните с четырёх шагов: обеспечение технической доступности контента, переработка 10–20 ключевых страниц, публикация убедительных доказательств и запуск базового мониторинга новой видимости через Search Console и GA4. Остальные шаги реализуйте после первого цикла наблюдений.
Нет. Можно лишь повысить вероятность: за счет структуры, извлекаемости, цитируемости, доказательств, авторства и более широкого круга публичных доказательств. Всё остальное — либо преувеличение, либо продажа иллюзий.
Верить, что достаточно просто ранжировать страницу. В среде ИИ уже конкурируют фрагменты, доказательства, авторство, видео, внешние упоминания и вся логика того, как бренд существует в публичном поле.
.webp)